THỜI LƯỢNG: 5 ngày (~40 giờ)
GIỚI THIỆU KHÓA HỌC
Khóa học Oracle Big Data Fundamentals Ed 2 hỗ trợ học viên tìm hiểu về dữ liệu lớn, các công nghệ được sử dụng và giải pháp của Oracle để xử lý dữ liệu lớn như Oracle Big Data Appliance, VM Big Data Lite.
Đồng thời xác định cách lấy dữ liệu thô từ nhiều nguồn khác nhau và học cách sử dụng cơ sở dữ liệu HDFS và Oracle NoSQL để lưu trữ dữ liệu, tìm hiểu về các tùy chọn tích hợp dữ liệu có sẵn trong Oracle Big Data bao gồm Oracle Big Data Connector để chuyển dữ liệu đến và từ Oracle Database, Oracle Data Integrator và Oracle GoldenGate cho Big Data, cung cấp khả năng tích hợp và đồng bộ hóa dữ liệu thống nhất dữ liệu quan hệ như Hadoop và Oracle Big Data SQL, truy cập tất cả dữ liệu lớn từ nhiều nguồn lưu trữ dữ liệu khác nhau như HDFS, NoSQL hoặc Cơ sở dữ liệu Oracle.
Và quan trọng là sử dụng Oracle Big Data SQL, Oracle Advance Analytics và Oracle Big Data Spatial and Graph áp dụng cho việc phân tích dữ liệu lớn.
MỤC TIÊU KHÓA HỌC
Sau khi hoàn tất khóa học, học viên có khả năng:
- Xác định dữ liệu lớn
- Mô tả Giải pháp dữ liệu lớn tích hợp của Oracle và các thành phần của Oracle
- Xác định phân phối Hadoop của Cloudera và các thành phần cốt lõi của nó và hệ sinh thái Hadoop
- Sử dụng hệ thống tập tin phân tán Hadoop (HDFS)
- Triển khai dữ liệu lớn bằng cách sử dụng giao diện dòng lệnh, Flume và cơ sở dữ liệu Oracle NoSQL
- Xử lý dữ liệu lớn bằng cách sử dụng MapReduce, YARN, Hive, Oracle XQuery cho Hadoop, Solr và Spark
- Tích hợp dữ liệu lớn và dữ liệu kho bằng cách sử dụng Sqoop, trình kết nối dữ liệu lớn của Oracle, sao chép vào Hadoop, trình tích hợp dữ liệu Oracle và Oracle GoldenGate cho dữ liệu lớn và Oracle Big Data SQL
- Phân tích dữ liệu lớn bằng cách sử dụng Oracle Big Data SQL, Oracle Big Data Spatial và Graph, và các công nghệ Oracle Advanced Analytics
- Sử dụng và quản lý Oracle Big Data Appliance
- Xác định các tính năng và lợi ích chính của Dịch vụ đám mây dữ liệu lớn của Oracle
- Xác định các tính năng và lợi ích chính của Dịch vụ đám mây dữ liệu lớn của Oracle - Phiên bản tính toán
ĐỐI TƯỢNG THAM GIA
- Application Developers
- Database Administrators
- Database Developers
ĐIỀU KIỆN THAM GIA
- Database Basics and Administration
- Exposure to Big Data
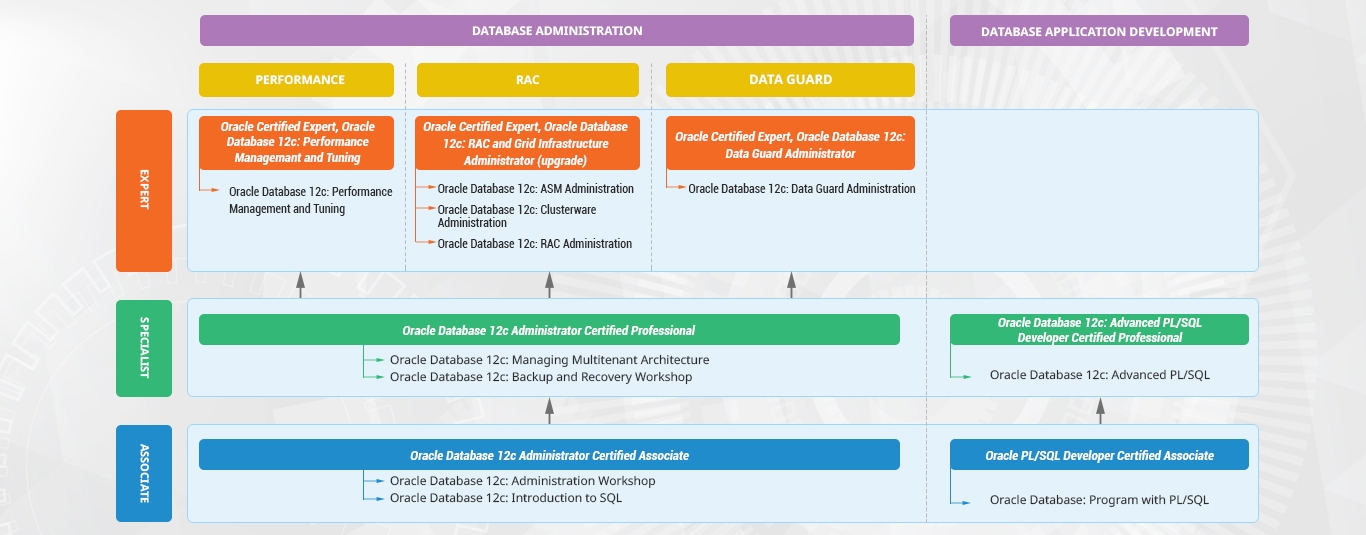
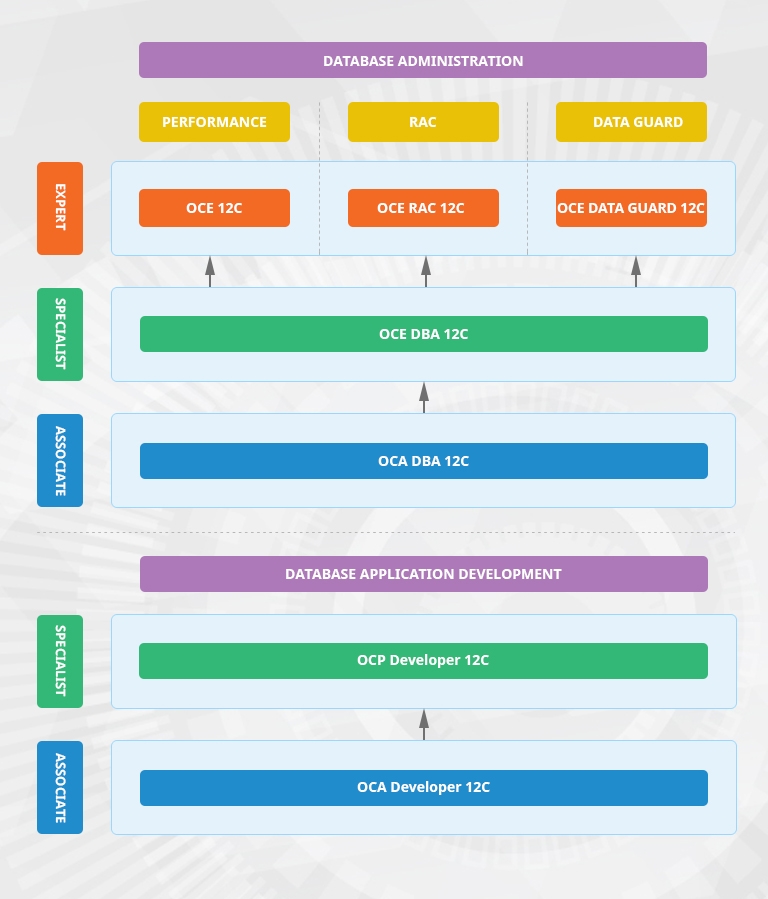
KHÓA HỌC LIÊN QUAN
CHỨNG NHẬN
Sau khi hoàn tất khóa học, học viên sẽ được cấp chứng nhận hoàn tất khóa học của Oracle.
NỘI DUNG KHÓA HỌC
Module 1: Introduction
- Reviewing the Available Big Data Documentation, Tutorials, and Other Resources
- Course Road Map
- Course Objectives
- Starting the Oracle BDLite VM and accessing the Practice Files
- Questions About You
- Oracle Big Data Lite (BDLite) Virtual Machine (VM) Home Page
Module 2: Introducing Oracle Big Data Strategy
- Big Data implementation examples
- Importance of Big Data
- Oracle strategy for Big Data: combining Big Data Processing Engines: Hadoop / NoSQL / RDBMS
- Characteristics of Big Data
- Big Data Opportunities: Some Examples
- Big Data Challenges
Module 3: Using Oracle Big Data Lite Virtual Machine and Movieplex Application
- Reviewing the Deployment Guide
- Oracle Big Data Lite VM Home Page Sections
- Introducing the Oracle Movieplex Case Study
- Oracle Big Data Lite VM Used in this Course
- Importing the Appliance File
- Downloading and Running 7-zip Files to create Virtual Box Appliance File
- Downloading and installing Oracle VM VirtualBox and its Extension Pack
- Staring the Big Data Lite VM and Starting and Stopping Services
Module 4: Introduction to the Big Data Ecosystem
- Cloudera’s Distribution Including Apache Hadoop (CDH)
- Apache Hadoop
- Types of Analysis That Use Hadoop
- CDH Architecture and Components
- Apache Hadoop Ecosystem
- Computer Clusters and Distributed Computing
- Types of Data Generated
- Apache Hadoop Core Components: HDFS, MapReduce (MR1), and YARN (MR2)
Module 5: Introduction to the Hadoop Distributed File System
- Sample Hadoop High Availability (HA) Cluster
- HDFS Files and Blocks
- Hadoop Distributed Filesystem (HDFS) Design Principles, Characteristics, and Key Definitions
- Interacting With Data Stored in HDFS: Hue, Hadoop Client, WebHDFS, and HttpFS
- DataNodes (DN) Daemons Functions
- Writing a File to HDFS: Example
- Active and Standby Daemons (Services) Functions
Module 6: Acquire Data using CLI, Fuse, Flume, and Kafka
- Kafka topics
- Additional Resources
- Viewing File System Contents Using the CLI
- What is Flume?
- Overview of FuseDFS
- Loading Data Using the CLI
- Reviewing the Command Line Interface (CLI)
- FS Shell Commands
Module 7: Acquire and Access Data Using Oracle NoSQL Database
- Oracle NoSQL models: Key-Value and Table
- Accessing the KVStore
- What is a NoSQL Database
- Accessing the CLIs (Data, Admin, SQL)
- Acquiring and Accessing Data in a NoSQL DB
- HDFS Compared to NoSQL
- Define Oracle NoSQL Database
- RDBMS Compared to NoSQL
Module 8: Introduction to MapReduce and YARN Processing Frameworks
- Data Locality Optimization in Hadoop
- Parallel Processing with MapReduce
- YARN Architecture, Features, and Daemons
- Hadoop Basic Cluster: MapReduce 1 Versus YARN (MR 2)
- MapReduce Framework Features, Benefits, and Jobs
- YARN Application Workflow
- Word Count Examples
- Submitting and Monitoring a MapReduce Job
Module 9: Resource Management Using Yarn
- Static Service Pools
- Cloudera Manager Dynamic Resource Management: Example
- Working with the Fair Scheduler
- Cloudera Manager Resource Management Features
- First In, First Out (FIFO) Scheduler, Capacity Scheduler, and Fair Scheduler
- Submitting and Monitoring a MapReduce Job Using YARN
- Job Scheduling in YARN
- Using the YARN application Command
Module 10: Overview of Apache Spark
- Benefits of Using Spark
- Running a Spark Application on YARN (yarn-cluster Mode)
- Spark Interactive Shells: spark-shell and pyspark
- Spark Application Components: Driver, Master, Cluster Manager, and Executors
- Monitoring Spark Jobs Using YARN's ResourceManager Web UI
- Word Count Example by Using Interactive Scala
- Spark Architecture
- Resilient Distributed Dataset (RDD)
Module 11: Overview of Apache Hive
- What is Hive?
- How is Data Stored in HDFS?
- Big Data SQL on Top of Hive Data
- Organizing and Describing Data With Hive
- Defining Tables Over HDFS
- Use Case: Storing Clickstream Data
- Hive Queries
- Hadoop Architecture
Module 12: Overview of Cloudera Impala
- Hadoop: Some Data Access/Processing Options
- Cloudera Impala: Programming Interfaces
- How Impala Works with Hive
- Cloudera Impala
- How Impala Fits Into the Hadoop Ecosystem
- Overview of Cloudera Impala
- Cloudera Impala: Supported Data Formats
- Cloudera Impala: Key Features
Module 13: Using Oracle XQuery for Hadoop
- XQuery Transformation and Basic Filtering
- XML Review
- Viewing the Completed Query in YARN's ResourceManager
- Running an OXH Query
- OXH Features
- Oracle XQuery for Hadoop (OXH)
- Using OXH: Installation, Functions, Adapters, and Configuration Properties
- OXH Data Flow
Module 14: Overview of Solr
- Cloudera Search: Features
- Overview of Solr
- Apache Solr (Cloudera Search)
- Cloudera Search Tasks
- Indexing in Cloudera Search
- Types of Indexing
- The solrctl Command
- Cloudera Search: Key Capabilities
Module 15: Integrating Your Big Data
- Comparing Big Data Processing Engines
- Unifying Data: A Typical Requirement
- Introducing Data Unification Options
- When To Use These Options?
Module 16: Batch Loading Options
- Oracle Copy to Hadoop
- Oracle Loader for Hadoop
- Apache Sqoop
Module 17: Using Oracle SQL Connector for HDFS
- Using OSCH
- Performance Tuning
- Loading: Choosing a Connector
- Parallelism and Performance
- Batch and Dynamic Loading: Oracle SQL Connector for HDFS
- OSCH Architecture
- Features
- Key Benefits
Module 18: Using Oracle Data Integrator and Oracle GoldenGate for Big Data
- Oracle GoldenGate for Big Data
- ODI’s Declarative Design
- Using ODI with Big Data Heterogeneous Integration with Hadoop Environments
- Using ODI Studio
- ODI Studio: Big Data Knowledge Modules
- ETL and Synchronization: Oracle Data Integrator
- ODI Knowledge Modules (KMs)Simpler Physical Design / Shorter Implementation Time
- ODI Studio Components: Overview
Module 19: Using Oracle Big Data SQL
- Query Performance Overview
- Benefits: Virtualizes data access across Oracle Database, Hadoop and NoSQL stores
- Overcoming Big Data Barriers
- Barriers to Effective Big Data Adoption
- Oracle Big Data SQL: The Hybrid Solution
- Deployment Options
- Using Oracle Big Data SQL
Module 20: Using Oracle Big Data Spatial and Graph
- BDSG: Graph Analysis
- Multimedia Analytics Framework
- Deployment Options for Oracle BDSG
- Oracle BDSG: Spatial Analysis
- Graph and Spatial Analysis: All About Relationships
- Additional Resources
- Strategy (supported platforms, etc)
- What is Oracle Big Data Spatial and Graph (BDSG)?
Module 21: Using Oracle Advanced Analytics
- OAA: Oracle Data Mining
- OAA: Oracle R Enterprise
- Oracle Advanced Analytics (OAA)
Module 22: Oracle Big Data Deployment Options
- BDA Hardware and Integrated and Optional Software
- Introduction to the Oracle Big Data Cloud Service – Compute Edition
- Running the Oracle BDA Configuration Generation Utility
- Administering and Securing the Oracle BDA
- Introduction to the Oracle Big Data Appliance
- Oracle BDA Mammoth Software Deployment Bundle
- Introduction to the Oracle Big Data Cloud Service
- Using the Oracle BDA mammoth Utility














.png)






